目次
テキストマイニングとは
テキストマイニングとは、テキストデータを統計学を使って正確かつ客観的に分析し、その特徴をつかんでいく方法です。
例えば、映画のレビューというテキストデータを収集し分析することで、その映画に関するユーザの評価、どんな感想が多いのかといった傾向が分かります。
また、ユーザの属性と組み合わせることで、「若い人にはポジティブな感想が多いが、高齢なネガティブな感想が多い」など、ユーザ属性ごとの特徴も見えてくるかもしれません。
テキストデータをただ読むだけでなかなか特徴を把握しにくいですが、テキストマイニングを使うことで、統計的に特徴を見いだすことができます。
テキストマイニングを行う際の注意点
テキストマイニングを始める前に以下のような点も確認したうえで進めるようにしましょう。
まずは数値データの分析も行う
数値データを調べれば分かることを、わざわざテキストマイニングで行うのは効率的ではありません。
まずはしっかり数値データの分析を行ったうえで、そこから見えない部分をテキストマイニングで探っていくような考え方で進めることが重要です。
分析の目的を決めておく
データ分析の基本でもありますが、目的がよく分かっていないままなんとなく分析をしていても思ったような成果は得られません。
例えば、「性別による口コミ評価の違いを明らかにしたい」といったように、どんなことを明らかにしていきたいのかを定めることで、効率的に分析を進めることができます。
データの集め方にも注意
たとえば、Instagramは若い女性に人気のSNSですが、写真や動画などがメインコンテンツのSNSなので、テキストデータの収集においては最適でないこともあります。
またSNSの場合、高齢者の利用率が低く、高齢者のデータが集めにくい可能性もあります。
このように、データの集め方によっては収集が上手くできないことがあったり、ユーザ属性に偏りが生じやすいなどの問題があります。
そのため、テキストデータを集めるにはどんな方法が適切なのかはしっかり考えたうえでデータ収集を始めることも重要です。
テキストマイニングの手順
ここからは、テキストマイニングの手順をご紹介します。
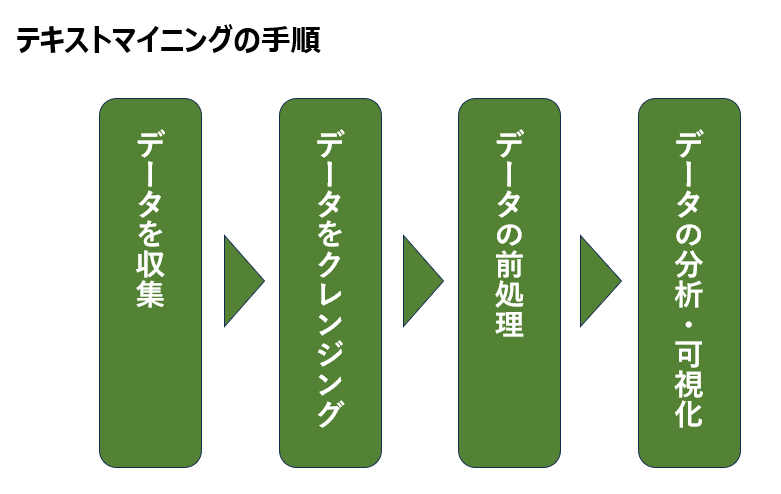
テキストデータを収集
まずは、テキストデータを収集するところから始めましょう。ECサイトや自社のHPの問い合わせなどから、CSVでテキストデータをエクスポートして集めるなどがオススメです。
また、大量のデータをWebから収集する場合は、スクレイピングなどの技術を使うのも一つの手段です。
ただし、スクレイピングを禁止しているWebサイトもあるので、実行する際はご自身の責任のもと、違法性がないよう細心の注意を払って確認したうえで行うようにしてください。
テキストデータをクレンジング
テキストデータを集めたあとは、そのデータをクレンジングします。
集めたデータにはたいてい分析に不要なものが含まれています。
例を挙げると、「」(括弧)や(^^)(顔文字)、そのほか絵文字や「!」「?」といった記号などがあります。
こういったものはテキストマイニングを行うときに邪魔になってしまうことがあるので、あらかじめクレンジングで取り除いておくことが重要です。
テキストデータの前処理
テキストマイニングでは、分析対象のテキストデータを、分析しやすくなるよう自然言語処理を行います。
そうすることで、意味のある単語やその関連性を整理し、分析が出来るようになります。
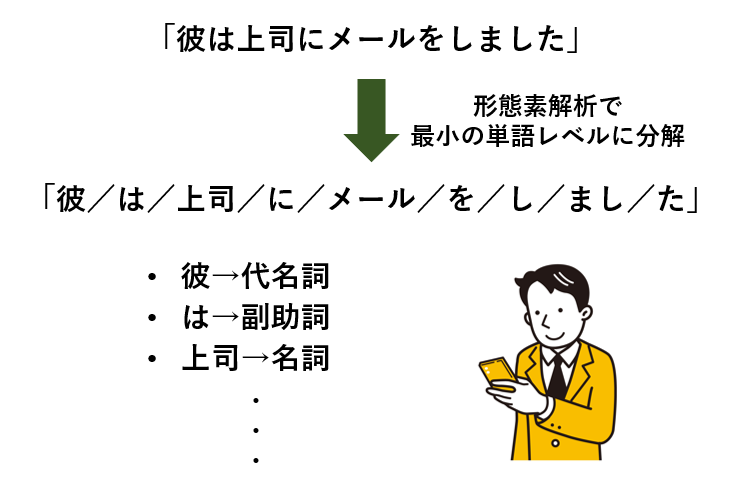
自然言語処理の代表例として、形態素解析があります。
形態素解析は、テキストデータ内の文章を「語」単位に分割し、語の品質を特定する方法です。
たとえば、「彼は上司にメールをしました」という言葉は、
「彼/は/上司/に/メール/を/し/まし/た」のように単語レベルに分解することができます。
そうすることで、「彼→代名詞」「は→副助詞」「上司→名詞」・・・のように品詞を特定することができます。
このようなデータの前処理を行うことで、データ分析ができるようになります。
テキストデータの分析/可視化
データの前処理まで出来れば、実際に分析を行い、得られた結果からどんなことがいえるのかを読み取っていきます。
分析手法としては、スコア(重要度を表す値)が高い単語を抽出し、値に応じた大きさで図示した「ワードクラウド」や、出現パターンが似た単語を線で結んで関係性を確認する「共起キーワード」、出現傾向が似た単語をまとまりとしてとらえられるようにした「階層的クラスタリング」などがあります。
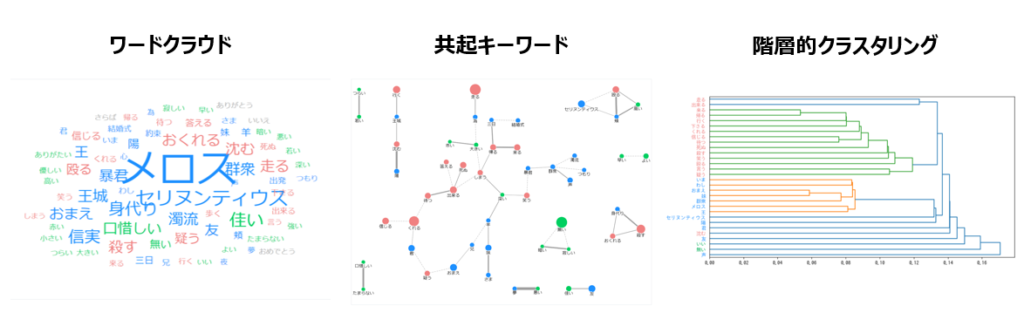
(参考)ユーザーローカルのサンプルデータをもとに作成
可視化の例
ユーザローカルを活用すれば、自然言語処理をせずに上記のような可視化、分析ができます。
例えば、以下のようなアンケートデータがあったとします。

こちらは、「Webサイト分析セミナー」を想定して作成したアンケートのサンプルデータです(実際に開催したセミナーのデータではありません)。
参加者が多数で自由記述回答をひとつひとつチェックできないような場合にもテキストマイニングを行うことで、回答の傾向を分析することがきます。
「勉強になったこと、良かったこと」の回答をもとに作成したワードクラウドが以下の図です。

こちらを見ると「実践」や「事例」といったキーワードが多く含まれていることが分かります。おそらく、具体的な事例などを元に解説した内容が参加者に好評だったことが推測されます。また、「実践」や「事例」などを含んだ回答のみを抽出して確認すればより具体的な回答の傾向を把握することができます。
同じく「もっと知りたいと感じたこと、改善点」の回答をもとに作成したワードクラウドが以下の図です。

こちらでは「ツール」というキーワード一番大きく表示されており、ツール活用に関する内容に課題があったことが推測されます。さらに同じデータをもとに作成した共起キーワードが以下の図です。
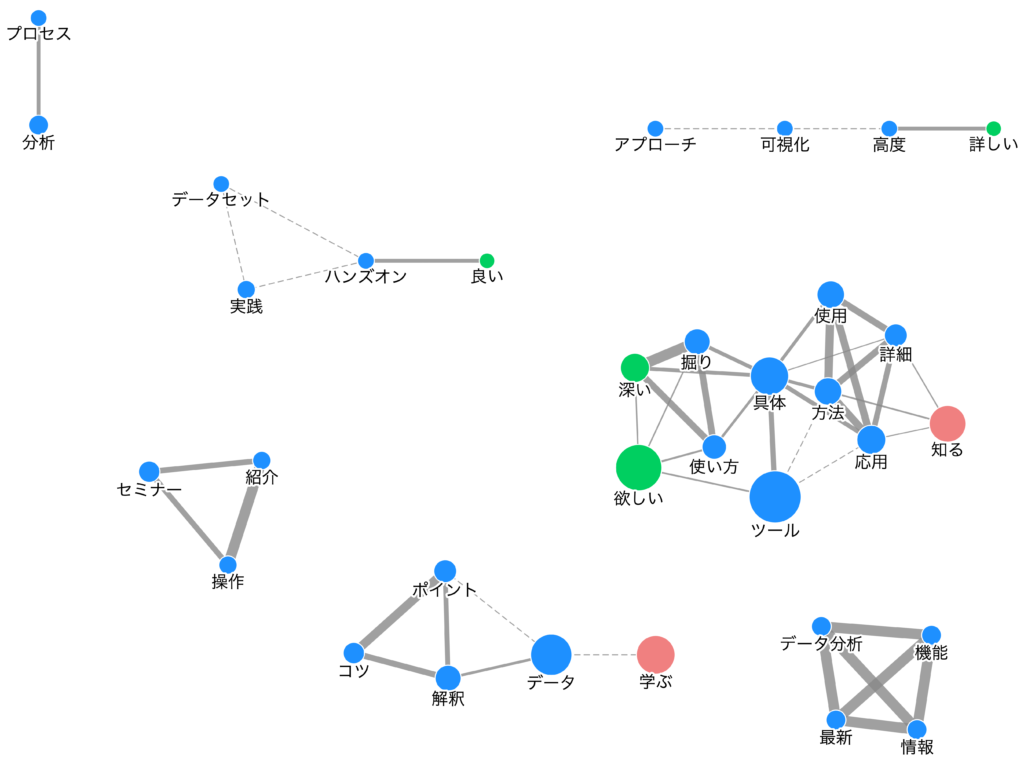
こちらを見ると真ん中の右あたりに「ツール」があります。ツールという単語と一緒によく使われている単語として「具体」や「応用」といったキーワードが挙がっています。この結果からおそらくツールの具体的な使い方や応用方法についてもっと知りたいと思った人が多くいることも分かります。
※ユーザーローカルAIテキストマイニングによる分析( https://textmining.userlocal.jp/ )
他にも様々な分析がありますので、気になった方は是非テキストマイニングについて学んでみてください。
オススメのテキストマイニングツール
ここからは無料で使えるテキストマイニングツール2つと、その特徴についてご紹介していきます。
ユーザーローカル
先ほども紹介したユーザーローカルは、Webサイト上でテキストマイニングができるツールです。
サイト上でできるので、ソフトのダウンロードなども必要なく気軽にテキストマイニングを体験できるというのがユーザーローカルのメリットです。
機能としては、ワードクラウドや単語出現頻度、共起キーワード、2次元マップ、係り受け解析、階層的クラスタリングなどがあります。
プログラミングの知識がなくても使えるツールなので、テキストマイニングをこれから始める方にオススメのツールです。
KH Coder
KH Coderは、テキストマイニングのフリー・ソフトウェアです。
Windows PCであれば、KH Coderをダウンロードするだけで、プログラミングの知識がない人でも簡単に分析を始めることができます。
データの前処理もできたり、出力に関する細かな設定ができる点もKH Coderのメリットです。
KH Coderは、様々な学会発表や論文でも活用されている注目のツールです。
テキストマイニングのビジネス活用例
ここからは、ビジネスのどういった場面でテキストマイニングが活用出来るのか、いくつかの活用例をご紹介します。
事例① ネットショッピングの口コミ
例えば、ECサイトを運営されているような企業様であれば、ネットショッピングの口コミ情報をテキストマイニングで分析することで、ユーザの感想やニーズを効率的に把握することが可能です。
男女別、年代別、地域別、など様々な属性情報と組み合わせてデータを見ることで、属性ごとの潜在的なニーズの発見につながるかもしれません。
事例② 会社口コミサイト
就職や転職の時に多くの方が参考にする会社口コミサイトの口コミを分析することで、どんな評価が多いのかを把握することが出来ます。
口コミで退職者からの年収や福利厚生に関する不満が多く見つかった場合、それらを改善していくことで退職率の低下につなげていくことができます。
事例③ TwitterやFacebookなどのSNS
SNSで自社のブランド、商品などに関する声を収集して分析することで、ユーザからの評価や潜在ニーズの発見につながります。
他にも、特定の人の投稿の特徴を分析するなどで、バズりやすい文章の特徴などを探していくのも面白いかもしれません。
まとめ
最近では、プログラミングの知識がない人でも簡単にテキストマイニングができるようになりました。
テキストを分析することで、これまで見えてこなかった課題やニーズ、改善案の発見につながることもあります。
無料のツールで簡単に始められますので、是非一度テキストマイニングを試してみてください。